Regard critique sur l’IA
Avant de plonger dans l’analyse de l’IA, il me semble important de rappeler que nous sommes dans une société capitaliste pour laquelle l’innovation est moteur de croissance indispensable à la stabilité de notre système économique.
Cette structure nous pousse à adopter une posture techno-optimiste. C’est-à-dire, à ne voir que le côté positif, les bienfaits (même hypothétique) d’une nouvelle technologie. Nous ne nous posons pas la question des problèmes potentiels ou avérés d’un technologie, et cela malgré les preuves indéniables des méfaits que nous pouvons observer après son adoption. Si nous osons émettre le moindre doute ou critique d’une nouvelle technologie (ou du discours techno-optimiste), nous sommes alors rapidement qualifiés de rétrograde anti-progrès (luddite) ou encore de partisans du modèle Amish.
Prenons l’exemple de l’automobile (électrique ou non). Elle nous est encore présenté aujourd’hui comme bienfait incontestable et incontournable d’une société moderne, porteuse de liberté, et ce, malgré les 80 millions de morts et 2 milliards de blessés depuis son invention. Sans oublier les innombrables conséquences des pollutions directes et indirectes (ex: 60% des micro-plastiques dans l’océan provienne des autos).
Ainsi, il en est de même pour ce qui est nommé ”IA” dans les médias. Cela nous est désormais présenté comme nouvelle réalité indéniable, que nous sommes forcés d’accepter. Elle nous apporterait plein de bienfaits et de progrès, sans qu’il n’y ait d’effets délétères dans la création et l’utilisation de cette technologie.
Qu’est-ce qu’une IA ?
Par principe, pour tout algorithme d’IA, nous ne savons pas comment la machine trouve son résultat. En effet si c’était le cas, nous n’aurions pas besoin d’IA et calculerons directement le résultat avec un algorithme spécialisé. C’est une boîte noire qui trouve un résultat qui nous semble crédible, sans que nous sachons comment il a été obtenu.
Les outils comme ChatGPT font parti d’une sous-catégorie d’IA appelé IA générative. Elles ont pour fonction de générer du contenu à partir de probabilité statistiques obtenues à partir d’une analyse d’un corpus de données. Ces probabilités sont compactées en un modèle qui sert donc de base a la génération de contenu. C’est pourquoi un outil comme ChatGPT est également appelé un LLM (Large Language Model), car reposant sur un modèle basé sur le langage texte conséquent.
Plus le corpus utilisé est grand et de qualité, meilleur sera le modèle.
La qualité peut être améliorer par des humains qui vérifient la pertinence des données et ajoutent des annotations pour aider la machine.
Ainsi, pour former son modèle, une entreprise va d’abord amasser une quantité immense de données qu’elle va ensuite faire pré-analyser par des humains.
Les premiers problèmes éthiques se posent ces données sont généralement amassées sans le consentement de leurs auteurs, ce qui résulte en un pillage massif de violation de droit d’auteurs, et l’analyse est un travail fastidieux souvent déléguer à des travailleurs pauvres des pays du Sud.
Il a été démontré que l’utilisation de ces modèles renforce les biais racistes et sexistes qui se trouvent dans leur corpus. Un autre problème majeur est l’empreinte écologique que cela engendre.
Désastre écologique
Lors d’une ruée vers l’or, ce sont les vendeurs de pelles qui deviennent riche. Dans le cas de la ruée vers l’IA, les pelles sont les centres de données (data center) et les machines à calculer (GPU) qui les habitent. C’est NVIDIA qui a un quasi-monopole pour ces dernières. Quant aux centres de données ce sont Microsoft, Google et Amazon qui sont en situation d’oligopole sur ce marché. À ce jour, ils investissent des millards pour construire de nouveaux centres pour l’IA. Cela est hautement problématique car ces centres de données et la fabrication des GPU nécessitent une consommation insoutenable en électricité, eau & métaux rares. Un serveur d’IA consomme 50 fois plus qu’un serveur normal.
De ce fait, l’empreinte carbone de Google a augmenté de 48% en 5 ans. C’est la trajectoire inverse de son objectif de carbo-neutralité pour 2030/2050. Les bilans de Microsoft et Amazon vont dans le même sens.
En Ireland, la consommation électriques des centres de données va bientôt dépasser la consommation de l’ensemble des foyers du pays, soit 31% (en Ireland plus de la moitié de l’électricité est produite par des énergies fossiles).
On estime que d’ici 2 ans, l’IA aura une consommation électrique l’équivalente au Japon. L’empreinte carbone est aujourd’hui équivalent a celle du Brésil.
À Memphis, Tennessee, Musk a fait installer sans autorisation plusieurs turbines à gaz pour alimenter son centre de données ou il entraîne l’IA de X. Ces turbines contribuent au smog dans une des villes les plus polluées des USA.
Les patrons de la tech (Altman, Musk, Gates) poussent pour une accélération de la production éléctrique — carbonée ou non — pour alimenter leurs serveurs. Pour eux le changement climatique n’est pas un problème car il serait solutionné par de la géo-ingénierie (techno-optimisme).
Au Québec nous avons la chance d’avoir Sasha Luccioni, une chercheuse sur l’impacte écologique de l’IA. Son TED talk sur le sujet est en ligne. Malgré le manque de transparence des entreprises d’IA, elle donne des estimations de l’empreinte écologique des différents modèles d’IA générative.
D’après une de ses études. Une IA générative utilise 30 fois plus d’énergie qu’une IA “classique” pour effectuer la même tâche.
Utilisation éthique possible?
Il serait possible d’utiliser ces algorithmes de manière éthique, mais pour cela il faudrait maîtriser la chaîne de production au complet. Par exemple en formant un modèle avec ses propres données uniquement. Cela nécessite une aisance et une maîtrise technique que le grand public n’a pas, et la qualité du résultat serait de toute façon moindre car elle dépend de la quantité de données utilisée.
Avec une vision utilitariste, on pourrait se dire que ce coût peut en valoir la peine si les résultats obtenus sont exceptionnels. Ce n’est pourtant pas le cas. La fiabilité des résultats est sur-vendu pour alimenter cette nouvelle bulle techno. Il arrive très souvent que l’algorithme invente des informations pour répondre à la question qui lui est posée. La véracité des informations générées n’est pas garanti, et c’est par construction.
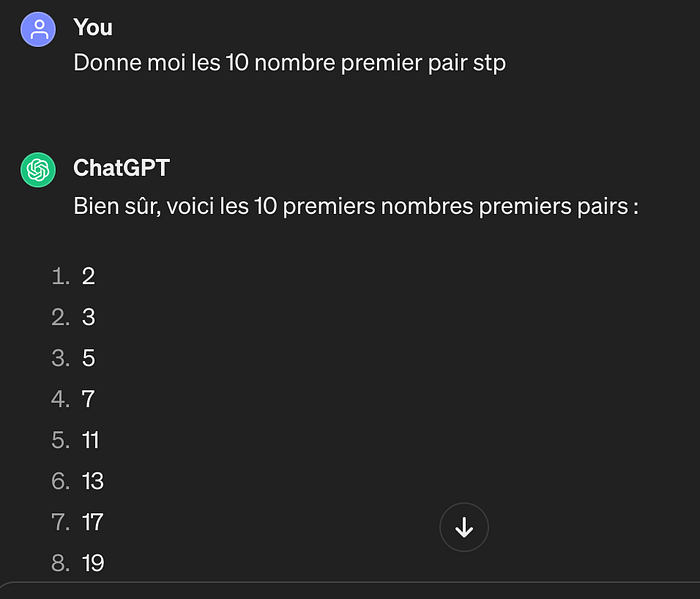
Par exemple, demandez à ChatGPT les 10 premiers nombres premiers pairs, et il vous trouvera les 10.
Une étude a démontré que pour faire des résumés de livres, plus des 50% des résultats présentaient des erreurs factuels.
Une étude récente démontre que les modèles s’effondrent lorsqu’une IA s’entraîne sur des données auto-générés. Ou encore, que les personnes qui l’utilisent à leur travail font plus d’erreurs avec que sans.
Ces outils ne sont en réalité utilisable que par les experts de leur domaine, capable de facilement détecter et corriger les erreurs générées.
Ces outils sont pour l’instant accessibles à tous gratuitement, mais cela est temporaire. Des capitaux privés sont massivement investis pour promouvoir ces technologies dans le but de créer et de monopoliser un nouveau marché. Ces investisseurs ne pourront offrir gratuitement ces outils gourmands en ressources encore longtemps. On voit déjà certaines compagnies changer leur offre pour devenir payante. Une fois le marché et le monopole établi ils n’hésiterons pas à détériorer et extraire davantage de leurs clients, comme le font le reste des plateformes web.
La tromperie est une culture dans le monde de l’IA. OpenAI n’a rien d’ouvert ou de libre, car il s’agit en réalité d’une compagnie privée détenu en parti par Microsoft qui garde secret ses données importantes pour son avantage concurrentiel. OpenAI est ainsi aussi “ouverte” que la République populaire démocratique de Corée est “démocratique”.
En conclusion, il semble très difficile de trouver une utilisation éthique et pratique de cette technologie. En 1979, IBM stipulait qu’une machine ne doit prendre de décision importante car elle ne peut être imputable. Il en est de même des résultats d’une IA générative. Il ne faut pas considérer comme avisé le résultat obtenu et toujours avoir un œil critique. Je vous invite à ne pas croire aux mythes véhiculés par le battage médiatique et vous rappelle que:
- Un programme n’est pas un humain et ne possède pas d’intelligence. Il est incapable de raisonner et planifier (ou même “halluciner”).
- Les résultats d’une IA générative ne sont pas déterministes. Un signe de ponctuation peut complètement changer le résultat obtenu.
- “Prompter” ne permet pas d’améliorer les résultats obtenus car tout se base sur le modèle de base qui ne change pas.
- Les résultats ne sont pas neutres, car les données pour former le modèle sont immanquablement biaisés et ont des angles morts.
- Une IA générative n’est pas une base de données ou un moteur de recherche. Les informations qu’elle génère ne sont pas fiables. Le programme ne peut pas stocker et récupérer un fait.
En résumé, voici ce à quoi nous contribuons lorsque nous utilisons une IA générative comme ChatGPT:
- Viol massif des droits d’auteurs
- Consommation insoutenable en électricité, eau & métaux rares (et pollutions associées)
- Accroissement de la concentration de pouvoirs des GAFAM
- Exploitation de travailleurs pauvres des pays du Sud
- Accentuation des biais racistes et sexistes
